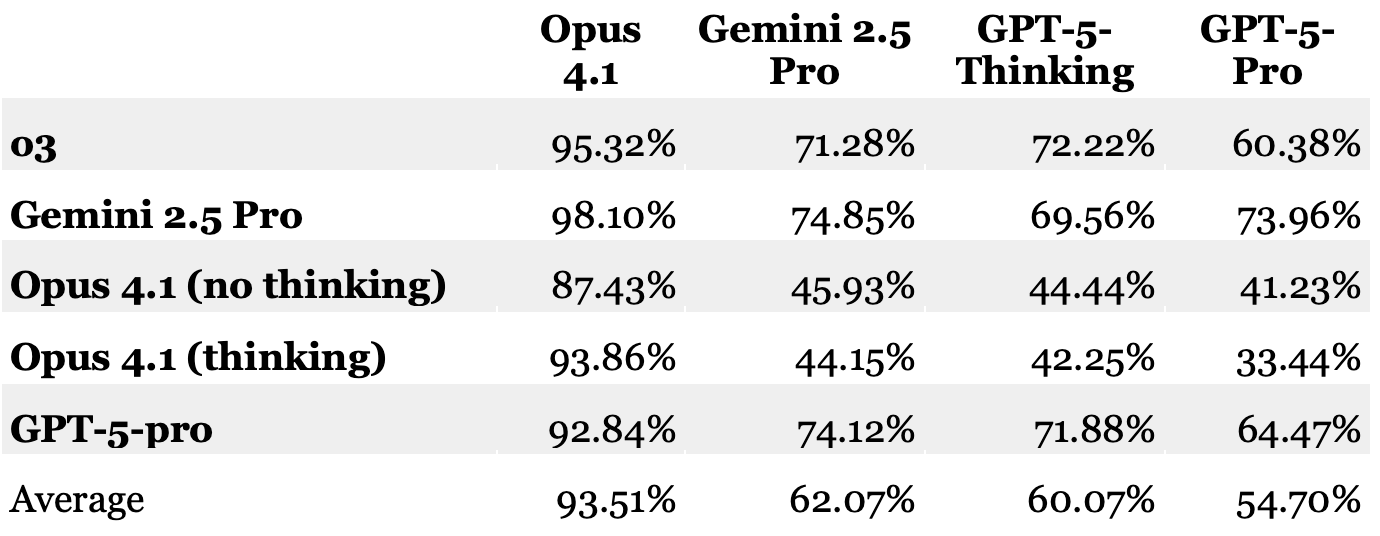
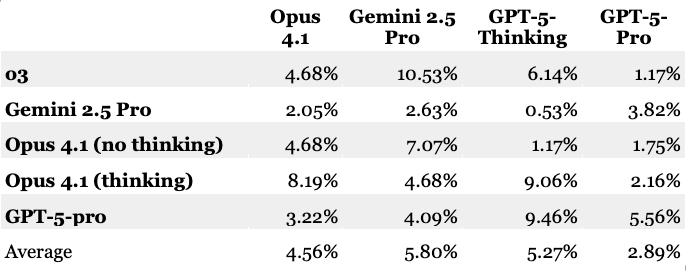
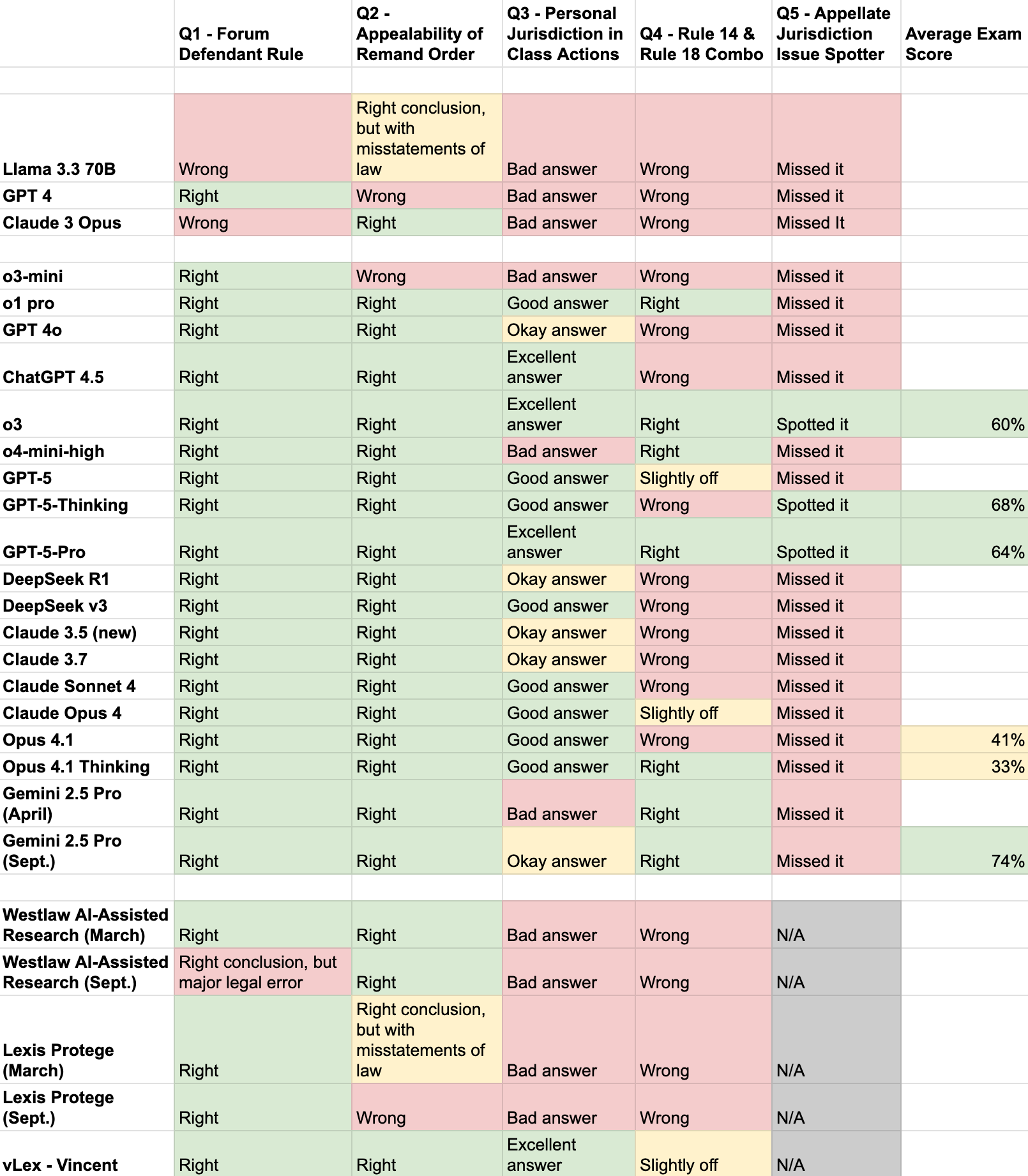
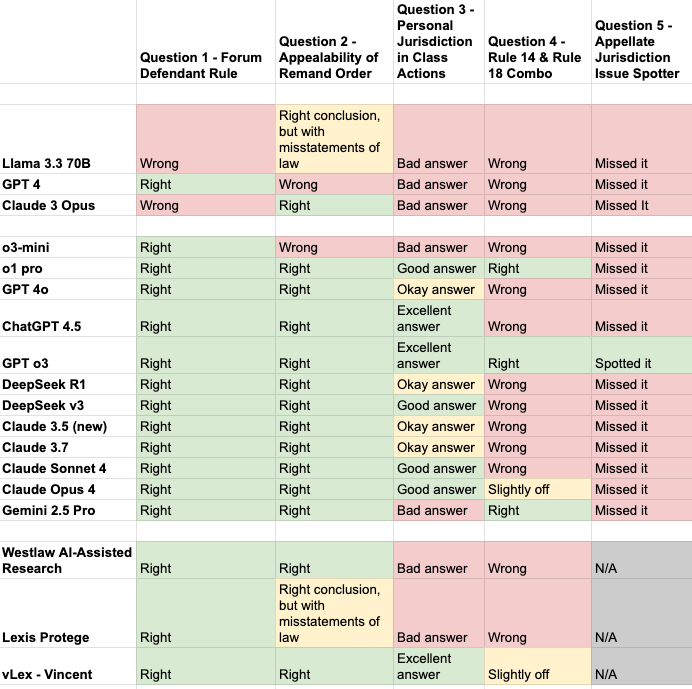
The low visibility of lawyers’ responsible AI use
A minor debate on X last week about lawyers' AI use led me to think I should write up a post on a topic I've been chewing on for a while: the problem of low visibility into lawyers’ responsible AI use. Without rehashing the debate, the starting point to me is this: many people are overgeneralizing from information about hallucinated cases (such as Damien Charlotin's useful database). This is not just a phenomenon happening on X. Although my research focus is on AI as an object of regulation and litigation, in my job as a law professor I also end up having lots of conversations with people about how lawyers are using AI as a tool for work. And hallucinated cases seem to be the thing that people focus on in many conversations about whether and how AI can responsibly be used in the law.
It makes sense that those kinds of cases are at the front of people's minds; they make frequent headlines and are great fodder for social media. And hallucinations are a real issue the profession has to deal with. Even federal judges are filing fake information in court orders! So the topic is important and real.
But we are missing visibility into another phenomenon that I think is more important: the regular use of AI by lawyers in responsible ways.1 When it comes to responsible AI use, the problem is this: we have reason to think there is a lot of AI use happening that is not clearly irresponsible. But there is not a lot of public visibility into the details: specific workflows, attempted safeguards and their efficacy, communications with clients, and so on. And if our collective impressions of AI use attend heavily to misuse while remaining only dimly aware of responsible use, that is a bad portent for regulation.
On thinking a lot of responsible AI use is going on: we know from survey data that AI use among lawyers is very widespread. You get different numbers depending on what you ask, but one recent good survey puts AI use at at least 55% of lawyers in law firms and 60% of lawyers in house. And just as importantly, that survey measured the intensity of AI use, finding that over half of the lawyers who use AI use it at least daily (or multiple times per day):
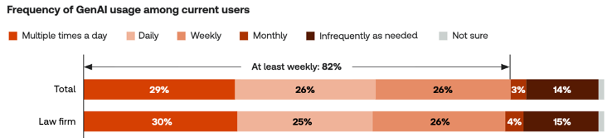
It is impossible to know, but I think the best working hypothesis is that a fair amount (and maybe most) of those uses are responsible uses. We are not seeing half of all litigators getting sanctioned for hallucinations. Clients appear to be on board—that same survey suggests a supermajority of corporate clients want their outside counsel using AI.
But what does that use look like? For the lawyers who are using AI to write briefs, how is that going? What are the hallucination rates like on different models, not on benchmarks but in the actual tumult of day-to-day practice? What are the more and less effective safeguards?
These questions are really important. We are at the start of a collective profession-wide (and society-wide) process of figuring out AI regulation. And that is going to mean developing rules and standards that effectively balance benefits and risks. If regulators, and the profession more broadly, have an outsized sense of AI-related harms and only a dim sense of benefits, that's not a recipe for well-crafted regulations.
But there are at least some incentives to keep the responsible use under wraps. Some incentives come from competitive pressures: If you or your firm has figured out a good recipe here, why broadcast it? Other incentives come from the uncertainty surrounding the norms of professional responsibility: because the ethical parameters around AI use are uncertain, going on the record in detail about AI use is sticking your neck out unnecessarily.
It's not all that hard, in one-on-one conversations, to find talented, responsible lawyers who are using AI tools in rigorous ways, applying quality checks and maintaining high standards. But there is not much public visibility into that category. And public visibility matters, as a necessary precursor to having a public conversation about acceptable uses and regulations.
The other problem is that the people who are loudly broadcasting positive AI messages are often not particularly trustworthy: there's a lot of hype and hucksterism. That creates a particularly noisy information environment, with dubious positive takes on AI in the law, well-reported instances of malfeasance, and a missing middle of accounts of everyday responsible use.
The low-visibility problem in lawyers’ responsible use of AI is in some ways a microcosm of broader AI regulatory discourse. Alongside debates about how to regulate AI, there is a loud and frequent conversation about "what can AI actually do?" And although there is a kind of hype that I think people understand well (beware businessmen's description of their own products), there is also a kind of reflexive cynicism that goes beyond a healthy skepticism into an inattention to real developments. A recent piece by Dan Kagan-Kans highlights how this can end up stifling useful political discussion. A baseline shared understanding of what AI tools can and do actually do is an important part of coming to a consensus (or even just having a healthy debate) about what the best path forward is.
Back to the legal profession in particular: It seems to me like this state of affairs is ripe for some entrepreneurial folks to come along and serve the role of information spreaders. In the private market that will probably take the form of consultants or trainers. There is also a lot more room for journalists or academics to peer into the world of responsible legal AI use. So hopefully this visibility problem is only temporary.
- "Responsible" needs a bit of elaboration here. The legal profession is only in the early stages of figuring out how the various self-regulatory rules that lawyers have (such as rules of professional conduct) apply in the many different situations where lawyers are using AI. So what I mean here is not "responsible" in the formal sense of compliant with all rules and norms (as those haven't been clearly established yet), but instead in the more colloquial sense: the use of AI tools in a way that is attentive to potential harms and downsides, involves safeguards, is transparent and doesn't involve deceit, etc. ↩