
Testing generative AI on legal questions—May 2025 update
The latest round of my informal testing
Two months doesn’t seem like such a long time, but when it comes to AI model releases a lot can happen. Back in March, I wrote about some informal testing that I have been doing of large language models on legal questions for the last couple of years. Since then, OpenAI, Google, and Anthropic have all released major new updates to their models.
This will be a short post. I won’t be writing a new post every time there is a new round of updates, but I did want to revisit this because there has been a meaningful new development on my testing in particular: there is now a model—OpenAI’s ChatGPT o3—that aces all of the questions that I give it. No model had done that before. In particular, no model had gotten what I labeled “Question Five” correct. As I described:
Question Five was an issue of appellate jurisdiction that was more “hidden” in the issue spotter—there was no direct text asking the reader specifically about appellate jurisdiction, although there was a general call to address any jurisdictional issues. Every model missed this. And most of my students missed this one too! But, as I tell my students, the world will not always give legal issues to you in a nicely identified and labeled form, so identifying an issue that is present without being told that it is present is an important legal skill. It seems like it’s a skill that the LLMs have yet to master, at least when it comes to appellate jurisdiction.
Well, it turns out “have yet to master” was only true for a few more days. Here is what my chart looks like now:
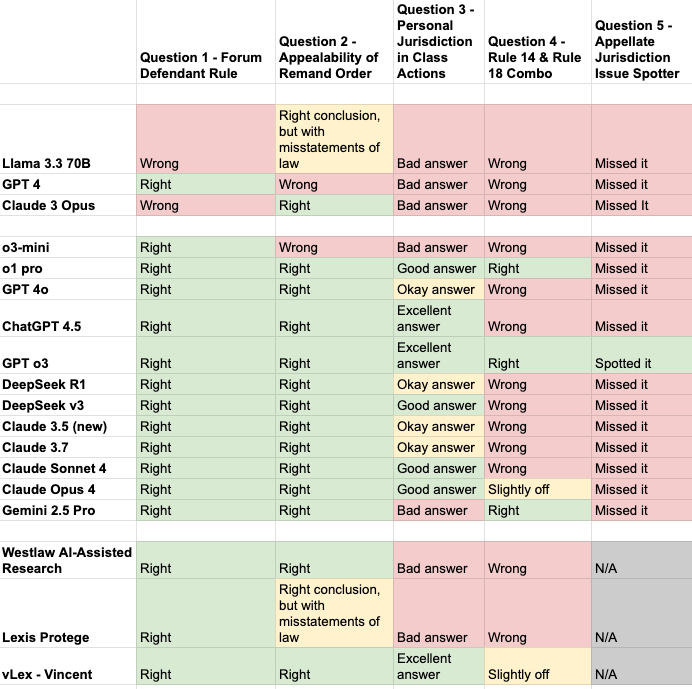
That completely green row in the middle is ChatGPT o3. Many have been impressed with o3 on a number of dimensions, both quantitative and qualitative. And in my personal experience, o3 does seem like a major step forward in analytical capacity, in addition to being much better at web search. It’s now the model that I use most often. Interestingly, as the chart reflects, Anthropic’s Opus 4 and Google’s Gemini 2.5 Pro still don’t “see” the issue for Question Five but do better than most of their predecessors on Question Four.
When it comes to testing models, it is probably time for me to go back to the drawing board and try to find some more questions that no current model gets right, to avoid “ceiling effects” that would make this kind of testing less informative about models’ relative capacities. In terms of comparing models to human students, though, it is worth emphasizing that Question Five was hard—only 5 of my 58 students got it right.
One methodological virtue of the questions that I have been testing is that they had pretty clear right and wrong answers, which made testing them easier. I am more hesitant to use questions whose answers require more judgment to grade, even though my exams have plenty of those questions as well (as is often the case with law school exams). I worry that I will be biased when evaluating AI capacity on those questions because I know the answers are written by AI. (That’s one reason that I particularly like studies of lawyers or law students using AI that use blind grading to evaluate outputs, e.g. the first study I discuss here.) But the set of questions that (a) have clear right and wrong answers and (b) AI tools continue to get wrong seems like it may just be getting smaller over time.
Interesting! Can you also test o4-mini-high? I'd be curious to see how it does on your test.