ChatGPT takes—and grades—my law school exam
Welcome to the latest in my series of informal tests on large language models in the context of legal questions. My first installment, back in March, compared many different models on legal questions of increasing difficulty. Of course, as luck would have it, OpenAI released its o3 model, a significant step forward in capability, right after I posted that—and Anthropic and Google followed shortly thereafter with Gemini 2.5 Pro and Claude Opus 4. So my second installment added those models, and noted that o3 was the first model to get the difficult “dog not barking” Question 5 right. This reflected what, to me, was the crossing of an important threshold: o3 and similar models are now capable enough to be productively used on a variety of legal tasks, even if there are still important limitations.
The world of generative AI continues to develop rapidly, and I’m back with another round of model testing. For this latest round, I wanted to add some new tests, since some models have started getting all of my previous questions right. The natural place to look was giving some of the models an entire law school exam. We know from a couple of sources (1, 2) that LLMs can pass and even score highly on law school exams. And an exam score based on many questions can be a more fine-grained way to compare different models than the simpler rubric I had been using.
The main challenge here is that law school exams often take a long time to grade. My exams, for instance, are a combination of longer essays and shorter essays, in which the score comes in large part from the accurate identification, discussion, and application of the law across many small details. This could make it somewhat impractical to use an exam to regularly test new models, as the grading time would rapidly become too burdensome.
But what if you use an LLM to grade the work of an LLM? I would not want to do that with student work, but as a way to quickly test the exam answers produced by new models it holds some promise. It is obviously much faster. But is it reliable?
Evaluating LLMs as graders
Before deciding to use LLM graders to assess LLM exam answers, I wanted to take a look and see if such an approach would yield informative results. The main goal, of course, is knowing whether LLMs give accurate grades. But if I had the time to grade a bunch of exams in the first place, then that would moot the whole need for this approach in the first place. So I decided to take an initial approach that examined two easier metrics: how much LLMs agree with each other on exam scores (between-grader consistency) and how similar an LLM’s scores are with itself when grading the same exam across different sessions (within-grader consistency). Looking at those numbers would at least be one way of detecting certain types of inaccuracy: if LLMs’ assessments of the same exam vary widely between graders or between sessions of the same grader, those would be strong indicators that they aren’t accurately grading the exam.
To start, I gave an old civil procedure exam I had written to five different models: ChatGPT o3; Gemini 2.5 Pro; Opus 4.1 (without extending thinking turned on); Opus 4.1 (with extended thinking turned on); and GPT 5-pro. I gave them all the same prompt, and copied their answers wholesale into individual Word documents. They were “anonymized” in that neither the document title nor the text in the document contained the names of the model that had written the answer (in case that might somehow bias the grading results).
I then gave each answer doc to each of four models to grade: Opus 4.1 (no extended thinking); Gemini 2.5 Pro; GPT-5-Thinking; and GPT-5-Pro. As a basis for their grading, I also uploaded an “exam memo” that I had written to my students after the exam in question, which went over the questions and answers to the exam in depth. I also included the grading rubric that I had used for grading the exam, which assigned detailed point values for different components of the answers to each question. Each model graded each exam answer in three separate sessions.
Here is the table of the results averaged over those sessions. The rows represent the models answering the exams, while the columns are the models grading the exams. The bottom row is the average score of each grader across all exams:
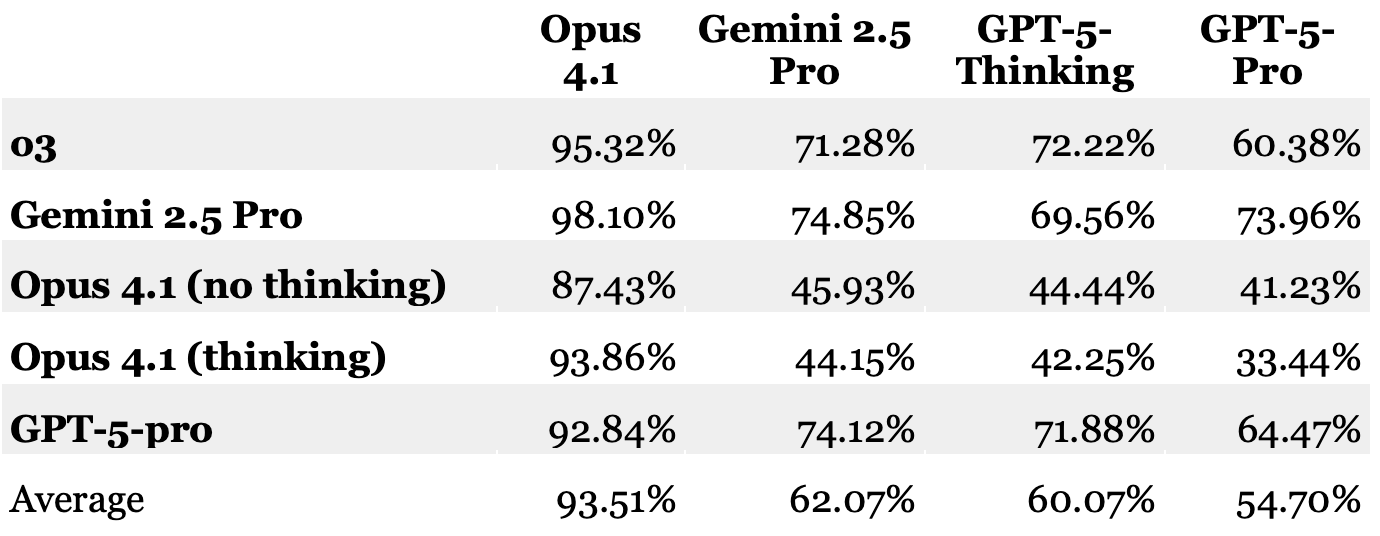
A few things are noticeable quickly. First, Opus 4.1—the sole non-“reasoning” model among the graders—has scores that are way, way higher than every other model. Second, Gemini and GPT-5-Thinking are often within a couple of points of each other, while GPT-5-Pro is sometimes in the same ballpark, but sometimes comes in a fair bit below. And also, leaving aside the Opus grader, both of the Opus exams scored much lower than the other three models.
Some quick spot checking of the exam answers themselves made it clear that Opus 4.1 is off base—some of these answers are good, but none is getting in the 90%–100% range. In response to my prompts, these models give long written analyses of their answers, rather than just putting out a numeric score, so it was possible to look at Opus’s reasons for its scores. Doing so indicated some major hallucinations; and the persistence of the high numbers suggested that this is a recurring problem. So Opus 4.1 is out as an exam grader.
What about the remaining three LLMs? The table above presents averages across three grading sessions, and gives you a sense of between-grader consistency. But what about within-grader consistency? There are a few ways you could assess that. I looked at the average absolute difference between the three scores that each model made for each answer. For instance, if Model X graded an answer at 75% the first time, 72% the second time, and 76% the third time, the average difference would be ((75–72)+(76–75)+(76–72))/3 = 2.67%. Here are the results:
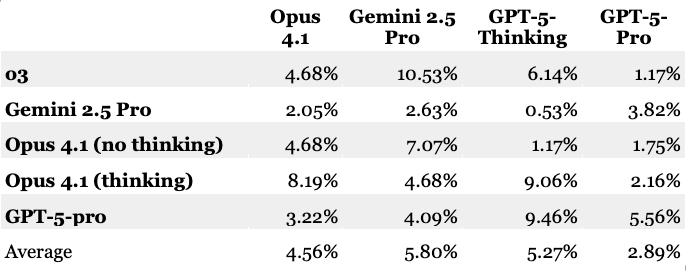
There is a pretty wide range here. There are a few instances where the average differences are around 10%. There are also some differences that are much lower, sometimes by the same grader. But if what you’re after is consistency, having a model that is sometimes consistent is not that comforting, if you also know that it sometimes has large departures.
As an interesting aside, looking for some context for these numbers took me on a brief detour into the world of human grading consistency. And it turns out that human graders have some consistency challenges of their own—such that a 10% deviation might not be terrible, if you compare it to between-grader consistency in scenarios with multiple human graders. This Swiss study, for instance, found that when three human evaluators with law degrees graded a set of legal question/answer pairs, their mean absolute error was 1.95 points out of 10—in other words, just shy of 20% (the study also found that GPT-4o as a grader was no worse than the human judges when it came to between-grader consistency). This report on the GRE found that on essays that are graded on a 1-to-6 scale, the rates for exact agreement between two readers is about 60%–indicating that 40% of essays have a disagreement of at least one point, which would be more than a 10% difference in score on a six-point scale.
But in any event, 10% inconsistency strikes me as higher than I would like. One of the models, fortunately, seemed to be doing better than the others. GPT-5-Pro achieved pretty good self-consistency scores, averaging differences in the 3% range.
Consistency, of course, is not accuracy. So I ran a series of spot checks comparing its grades to my own judgment across a number of different questions and exam answers. Its analysis tracked my own closely, although not perfectly—there were occasional moments where it awarded a slightly higher or slightly lower grade than I would have. But these were few in number and low in magnitude—it never departed dramatically from what I would have done, and it usually didn’t depart at all.
This is, again, a very informal set of tests—I wouldn’t take this as justification to use GPT-5-Pro to grade anything where there are meaningful consequences (such as actual work in a real school context). But for purposes of my informal model testing, it strikes me as good enough: a model that tends to hew pretty closely to my own assessments (based on detailed rubrics that I wrote and uploaded), and is mostly self-consistent over time, with only small departures when there are differences. So I used its scores (averaged across three readings) as the basis to grade the performance of several models on the exam overall.
And here are the results, added to an updated version of my original set of five questions across many models:
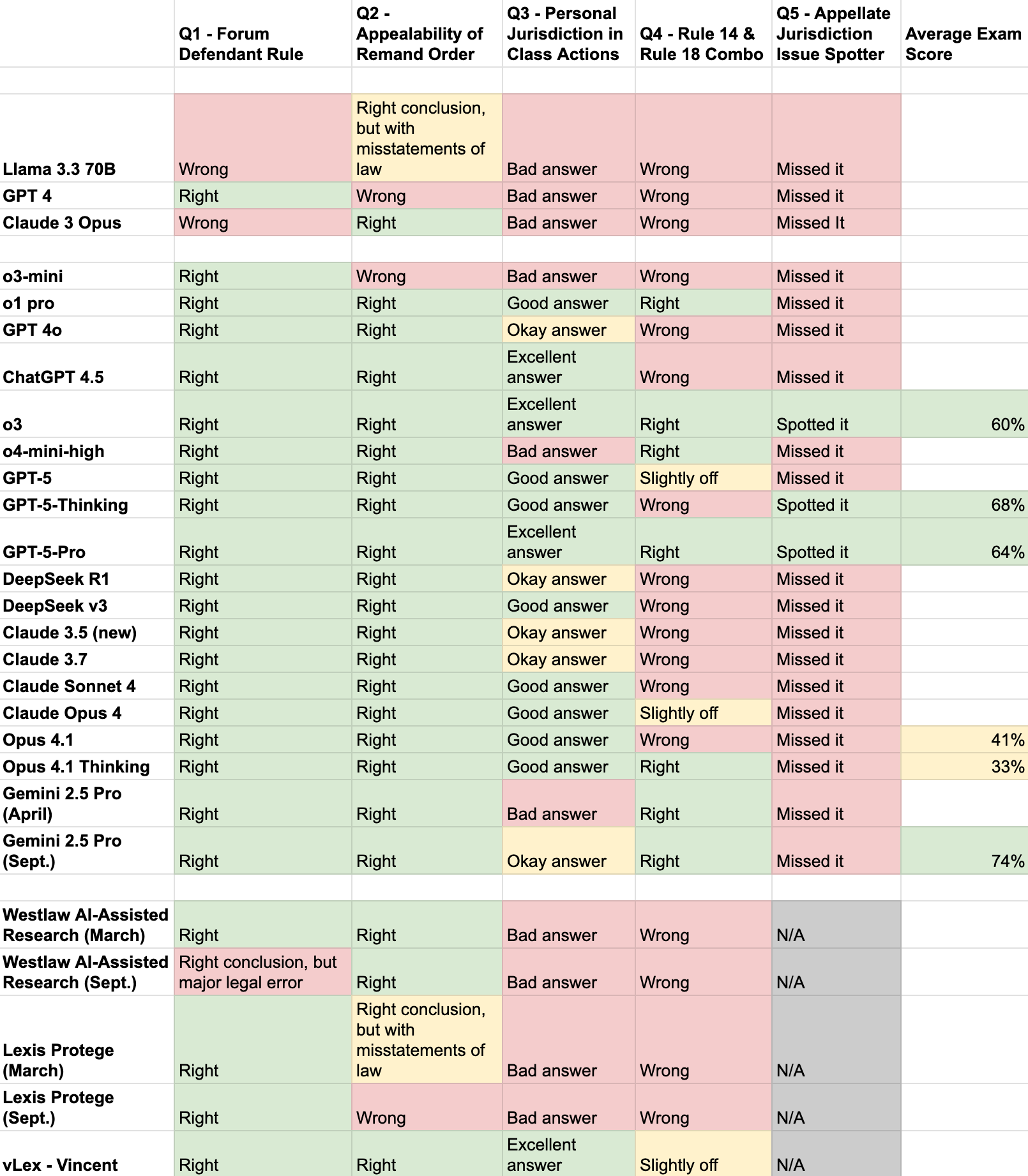
This is starting to get cramped—on the next iteration, I’ll leave off a lot of the older models, just to make things easier to read. But for now, a few things to note:
- On the first five questions, GPT-5 and GPT-5-Thinking did not outperform o3. This is probably not that surprising. GPT-5 itself functionally acts as a router between different models, and may have used a model to approach these questions that was less powerful than o3. GPT-5-Thinking, meanwhile, is (in my experience) roughly comparable to o3, and did get the hardest question (Question 5) correct—one of the only models to do so.
- In terms of exam performance, the results fall into roughly two groups. GPT-5-Pro, GPT-5-Thinking, o3, and Gemini 2.5 Pro all got pretty good results—roughly in the A- to A range, depending on the curve. The Opus results were much worse, though, including with Opus 4.1 running its extended thinking mode. This surprised me.
- For a few products (Gemini 2.5 Pro, Westlaw, and Lexis), I ran updated tests. These companies seem to be less interested in launching new models with new names every few months, but my sense is that they may still be doing some modifications on the back end. But, in any event, the results did not indicate improved outcomes for any of them.
- Westlaw and Lexis’s dedicated legal AI products continue to perform worse than the best generalist AI models. I wonder if / when that will change.
Now that I’ve got my automated exam-grading system up and running, it will be easy to test new models that come out, and I’ll provide further updates here as events warrant. It has been a few months since there have been big updates from the major model developers other than OpenAI, so that may be sooner rather than later. In the meantime, I’d welcome any thoughts or suggestions—I’ve enjoyed hearing from readers of these posts over the last few months.